文本分类模型比较
https://github.com/brightmart/text_classification
| Model | fastText | TextCNN | TextRNN | RCNN | HierAtteNet | Seq2seqAttn | EntityNet | DynamicMemory | Transformer |
|---|---|---|---|---|---|---|---|---|---|
| Score | 0.362 | 0.405 | 0.358 | 0.395 | 0.398 | 0.322 | 0.400 | 0.392 | 0.322 |
| Training | 10m | 2h | 10h | 2h | 2h | 3h | 3h | 5h | 7h |
fastText是word2vec作者提出来的,直接把文本中的单词的词向量进行相加,和词袋模型比较类似,速度很快,但是忽略的词语前后关系。
而TextCNN效果比较好,训练时间适中,实际相关应用和博文也比较多。其他模型没试过。
TextCNN基本原理
原论文:https://arxiv.org/pdf/1408.5882.pdf
具体实现: http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/
由于CNN在图片上分类效果很好,卷积具有局部特征提取的功能。Yoon Kim在2014年提出利用CNN进行文本分类。
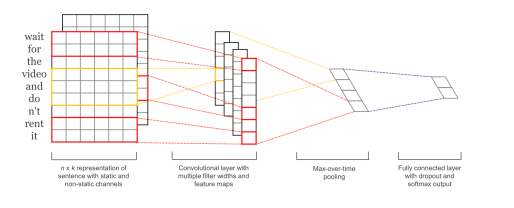
模型主要分为词嵌入层,三个卷积层,三个池化层和softmax层。
第一层词嵌入层把文本索引序列,也就是原始输入转换成词向量,如[1,2,3,4]四个单词的输入变成[[0.1, 0.2, 0, 0.4], [0.1, 0.2, 0, 0.4],[0.1, 0.2, 0, 0.4],[0.1, 0.2, 0, 0.4]],词向量不是从预先训练的word2vec模型获得的,而是从当前语料中学习的。后面的和普通的CNN模型基本一样,只是卷积核大小和池化窗口不同。
下一层就是三个卷积层,利用不同窗口大小的filter进行扫描,比如每次扫描3,4,5个单词,如上图的第一层的红色框大小是26。Filter大小分别是扫描窗口大小词向量大小,因为一行就是一个单词,拆分没有意义,因此卷积核宽度是矩阵宽度6。
每个卷积层进行卷积操作之后,把提取的关键信息,如第二层的向量阵,分别交给最大池化层,最后一层把三个池化层相连接,最大池化层进行数据压缩,只保留池化窗口内的最大值,池化窗口大小是[sequence_length- filter_size[i]+1,1]。
中间有全连接神经网络和防止过拟合的dropout层。
最后使用softmax层进行分类, 得到类似 [0.1, 0.9](二分类)的输出。
模型相关参数:
filter_sizes 每次滑动窗口的大小
embedding_dim 词向量长度
sequence_length 输入序列的最大长度,超过的截断,不足的补停止符
num_classes 分类数
vocabulary_size 语料库的词典大小
embedding_size 词嵌入层的参数,词向量的大小
num_filters 卷积核的个数
以上是根据我自己理解写得,刚学习没多久,理解不是很深,可能有错误。
文本预处理
分词,遍历所有文本,构建词汇map,记录最长文本长度。
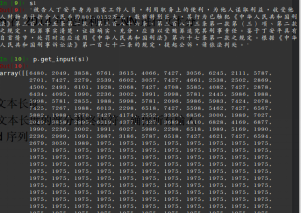
对于每一个文本,首先进行分词, 长度不足最长文本长度的部分补终止符,确保所有输入长度相同,再把单词映射成索引,因此文本变成id序列。如下图1975是补充的终止符的索引。
TextCNN代码说明
├── ./data
│ ├── ./data/gov # 训练数据,重庆的判决书
│ │ ├── ./data/gov/neg.txt
│ │ └── ./data/gov/pos.txt
│ ├── ./data/gov_test # 测试数据,天津的判决书
│ │ ├── ./data/gov_test/neg.txt
│ │ └── ./data/gov_test/pos.txt
│ ├── ./data/README.md
│ ├── ./data/rt-polarity.neg # 原代码语料是英文消极短语和积极短语
│ └── ./data/rt-polarity.pos
├── ./data_helpers.py # 数据读取
├── ./model.py # 训练模型
├── ./predict.py # 预测
├── ./__pycache__
│ ├── ./__pycache__/data_helpers.cpython-36.pyc
│ └── ./__pycache__/predict.cpython-36.pyc
├── ./README.md
├── ./vocab.pkl # 序列化对象,包含单词索引,最长文本长度
├── ./weights.001-0.9834.hdf5 # 按训练轮次-准确率保存的模型
├── ./weights.002-0.9905.hdf5
└── ./weights.007-0.9917.hdf5
第一类数据:
第二类数据:

训练模型:
Python model.py
测试评估模型:
Python predict.py
预测单独某个段落: