文章题目
Length Adaptive Recurrent Model for Text Classification
文章来源:CIKM 2017
作者:Zhengjie Huang
第一单位:Sun Yat-sen University, Guangzhou, China
源码:链接: https://pan.baidu.com/s/1uLBBkzUhFXAg2wcj6HvDVA 密码: thxt
拟解决的主要问题
当前的文本分类模型,如LSTM,在对文本进行分类时,会把该文本所有单词全部读取作为输入。而从人的角度来看,实际上只需要文本的一部分,就足够判断文本的类型。
全部读取文本作为输入,随着文本长度增加,时间复杂度会大大提高,如何对现有模型加速也是个优化问
题。循环神经网络是一个bias model, 受文本结尾的内容影响比较大,但是像新闻等文本主要内容在文章开头的标题中,反而结尾的文本变化比较大。
研究内容
提出LARM模型,通过在LSTM模型上加入agent,使之能够自动决定读取文本的长度用于文本分类,加速训练过程的同时保持分类准确率甚至在某些方面—在文本前后添加噪声padding会有更好的性能。
基于部分可观察马尔科夫决策模型设计训练过程,解决复杂度指数爆炸的问题,达到线性级别。
LARM模型可视化和原理验证,以及性能对比。
文章创新点
以往的length adaptive模型,大多数是在图像和语音领域,本文是文本领域,不过模型结构十分类似。
在分类模型从读取文本方面切入点做研究的,的确有类似的算法,但是它们有的是基于语句层面的,而不是单词层面,是把读取过程当作马尔可夫决策过程通过强化学习来实现;还有的是通过跳过一些单词,而不是动态决定读取的长度。本文是在逐单词读取过程中,动态决定读取长度的新方法
技术点细节
LARM模型分为三个部分,Reader,Agent,Predictor,就是在普通的LSTM上加了一个Agent.
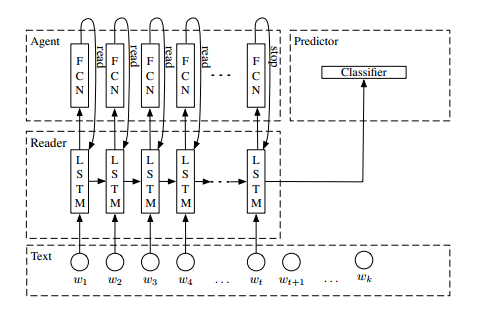
Reader:采用LSTM网络结构作为reader,接收[w1,w2,w3,…, wk]作为输入,一次读一个单词作为输入,如果Agent决定继续读取,将下一个单词和当前LSTM的输出作为下一个LSTM的输入。
Predictor:一个线性分类器,对Reader的输出进行softmax分类,得到最终分类结果。
Agent:一个两层的全连接神经网络,激励函数用的sigmod,决定是继续读取单词到Reader还是调用Predictor输出结果。
未来研究点
因为本文提出的模型,受agent判断结果的影响比较大,因此可以考虑多个agent的模型,然后选出最优的agent。
将本论文提出的模型结构,可以同样类似地应用在CNN或者LSTM混合模型中。
本文决定文本长度的方式是判断何时停止读取,反过来思考,一个能够判断何时开始读取的模型同样是一个新的研究点。
个人总结
这篇论文针对LSTM处理文本的特性,发现了它在处理长度不一文本方面的潜在问题,并提出了自己的模型进行了优化。
LARM 模型对头部和尾部padding都能较好地处理,但是文中没有和dynamic_rnn进行对比。
既然能够处理头部padding,那么未来研究点里的判断何时开始读取是否有必要或者效果会不会不好?